

嫌なこといいますが、6月って祝日ないんですよ。
Table of Contents
忙しい人向け
mspec という Claude Code 向けの仕様駆動開発(Spec-Driven Development)フレームワークを作っています。
ドキュメントは tubone24.github.io/mspec/ にまとめています。
はじめに
最近のAI駆動開発では、何かしらの仕様駆動開発フレームワークを使う機会が増えました。
いろいろなフレームワークを使い込んでいくうちに、もっとこうしたいという気持ちがあふれてきました。
ならば作っちゃおう、ということでmspecを作りはじめることにしました。
この記事では、まず実際にmspecで小さな機能を1つ作ってみる流れを見てもらい、そのあとで設計思想まで踏み込んでいきます。
まだ私自身がドッグフーディングしながら少しずつ育てている段階なので、荒削りな部分も多々あります。 が、設計の意図とともに見ていただければ嬉しいです。
仕様駆動開発で感じていた困りごと
mspecは、仕様駆動開発で繰り返し遭遇する困りごとを出発点に設計されています。
私はこのあたりがよく壁としてぶち当たりました。
Spec Drift(仕様の漂流)
いわゆる仕様とコードがズレている状態です。
コードは変更されているのに元になっているはずの仕様ドキュメントは前のまま、仕様が正しいのか、コードが正しいのか、本番の挙動から逆算しないとわからない という事態になります。
さらに厄介なのが、ある実装がどの仕様変更のために書かれたのか、その根拠になった仕様変更を後から追えない点です。
コードから変更の文脈を辿れないので、リファクタや削除のたびに、このコードを本当に消していいのかという確認コストが発生します。
(git運用を整えて単一のコミット点で仕様ドキュメントとコードをコミットしていれば、git logなどで追うことは可能ではあります)
ズレたあと、ドリフトを検知して仕様と実装を揃えるのは、なかなか難しいんですよね…。
AIが書くドキュメントの読みにくさ
仕様駆動開発フレームワークを回すと、大量のArtifact、つまりMarkdownファイルが生成されます。
困るのは、その中に 読み手や目的が混在しているドキュメント が大量に含まれることです。
後続の実装タスクでAIエージェントの生成ブレを抑えるためだけに書かれた詳細な手順書と、人間が設計の意図を確認するための概説が、Artifactに混ざっています。
特に私が辛いと感じたのは、実装を自然言語でなぞったタスクリストの存在です。
ある程度コードが読める人間にとって、次のような自然言語で書かれた実装手順の記述は、コードを読むよりも圧倒的にイメージしにくいものです。
○○クラスに△△メソッドを実装し、引数として〜〜を受け取り、〜〜を返す
コードであれば、関数ジャンプとか使って確認できるところを、自然言語で書かれるととてもじゃないけど追えないです。
そんな実装手順をレビューで人間に読ませる設計になっていると、実装コードを直接見るよりも理解のコストが高い逆転現象が起きていると感じました。
LLMがLLMを採点する閉鎖ループ
そして個人的に一番気にしているのがこれです。
仕様を書くのも、レビューするのも、テストを書くのも、実装するのも、同じくらいの能力のモデル だったとしたらどうでしょう。
仕様駆動開発フレームワークの動き自体は、基本的にはエージェントスキルで定義された手順でしかありません。
それはそれでいいのですが、各ワークフローの決定的なポイントでLLMがLLMを採点するような設計になっていると、AIエージェントの確率的な振る舞いがそのまま確実性に影響することになります。
LLMの確率的な振る舞いを、どこまで許容し、どこから決定論で締めるかが、ずっと悩みのポイントでした。
生成AIで形骸化するTDD
AI駆動開発をしていると、TDDの文脈によく出会います。
Kent Beck が2002年に書籍 Test-Driven Development で体系化したTDDのリズムは、 Red → Green → Refactor の3拍子です。
動かない小さなテストをまず書き(Red)、それが通る最小のコードを書き(Green)、重複と汚れを取り除く(Refactor)という手順です。
AI駆動開発をしていると度々TDDで実装するという指示に遭遇することが多いです。それはTDDがAI駆動開発においても理にかなっているからだと思います。
ところが、生成AIにこのリズムを実行させると、表面的にはRed→Greenに見えるのですが、テストを書く時点でAIの頭の中には実装イメージができてしまっているような振る舞いをすることが多いです。
その結果出てくるのが、カバレッジを上げるためだけのモック差し込みテストや、実装の振る舞いではなく実装そのものをコピーした検証コードの類です。
しかも、テストが落ちると平気でテストを実装に合わせて書き換えるような変更をしてくることもあるので、Red→Greenの順序が崩れていてもAIエージェントのなかでは、ちゃんとテスト書いて通しましたとなってしまいます。
根深い問題だと思います。
まず触ってみる
ここまでが動機です。mspecの仕組みの話に入る前に、まず実際にmspecで小さな機能を1つ作る流れを見てもらうのが早いと思います。
例として、あるプロジェクトにドキュメント全文検索の機能を足すケースを考えます。
インストールと初期化
mspecはnpmパッケージとして配布しているので、グローバルに入れます。
npm install -g @mspec/cli
mspec --version
プロジェクトのルートで mspec init を実行すると、 .mspec/ の設定一式、 memory/constitution.md(プロジェクト憲法)、そしてClaude Code向けの .claude/commands/・.claude/skills/・.claude/agents/ が生成されます。
初期化時にテスト実行コマンド(vitest run など)を聞かれるので、ここで合わせて設定しておきます。
変更を始める
mspecは変更(change)単位で動きます。Claude Codeのなかで /mspec:new スキルを叩くと、変更の名前やどんなリクエストかをAIエージェントが対話的に聞いてきて、changes/2026-05-29-HHMMSS-add-search/のようなディレクトリを切ってくれます。
このディレクトリに、今回の変更だけの仕様・設計・タスクがまとまっていきます。
同時にmspec Web UIが、http://localhost:3847 でバックグラウンド起動して、これ以降に生成される成果物をブラウザで眺められます。

止まるたびにアーティファクトを確認する
mspecのワークフローは、Claude Codeのスキルとして定義されています。
なので、/mspec:newのあと打つコマンドは/mspec:continueのみで基本的に完結します。
開発者の仕事は、各ステップが止まったときにアーティファクトを確認し、意図と合っているか判断することに集中します。
/mspec:new # 変更を開始する
/mspec:continue # ステップを進める。block: true で止まったら確認して、また叩く
/mspec:continue を叩くたびに、proposalを書く・プロトタイプを出す・Delta Specを起こす・research / designを固める…とステップが進みます。
ステップが止まったとき、何をどう確認するかは、doc_type が参考になります。
Explanation(理解志向)なら設計の意図を読み込み、Reference(情報参照)なら全部読み込まず気になる箇所だけ参照する、という具合です。
先ほどのドキュメント全文検索を追加する例で、実際に追ってみましょう。
まずは要求を出してみる
Proposalステップでは、先ほど/mspec:newコマンドで作られた概要を元にClaude CodeからAskUserQuestionの形で、どんな検索機能が欲しいか、検索対象のドキュメントは何かといった要求の深堀り質問が次々飛んできます。
あなたは、docs/配下のMarkdownを全文検索できるようにしたい、結果にはスニペットを出したいといくつか提示される選択肢に返答するだけで、proposal.mdが生成されます。

Markdownの中を開くと、Why・Goals・Non-Goals・Open Questionsがこんな形で整理されています。
Why: 現在
docs/配下のMarkdownはキーワード検索ができず、目的のページを見つけるためにファイルを手動で開く必要があるGoals:
docs/配下のMarkdownを全文検索できる。結果にはスニペットを表示するNon-Goals: リアルタイムのインデックス更新。外部ドキュメントの検索
Open Questions: インデックスの更新タイミング(ビルド時?起動時?)→ researchステップで調査
自分の意図と食い違っていなければ /mspec:continueで先に進み、違っていればAIエージェントに再度返信する形で要求を整えていきます。
仕様として形になっているか確かめる
次のステップは、delta specを作成する段階です。今回の要求(proposal)を満たすこのシステムへの変更の仕様を書いていきます。
Function Requirement(機能要件、FR)は、EARS(Easy Approach to Requirements Syntax) という記法で書かれます。
「〜できる」という曖昧な文体ではなく、条件・主語・振る舞いが一意に決まる形式として広く使われています。
FR-001:WHENユーザーがキーワードを入力したとき、システムはSHALLdocs/配下のMarkdownを全文検索し、マッチしたドキュメントの一覧を返す
FR-002:WHEN検索結果が表示されるとき、システムはSHALLマッチ箇所のスニペットをハイライト付きで表示する
と要件が整理されたspec.mdが出てきます。
そして各FRには、受け入れシナリオが Gherkin(Given/When/Then) で紐づきます。
Scenario: キーワードで検索する(FR-001, FR-002)
Given docs/ 配下に3件のMarkdownがインデックス化されている
When ユーザーが “検索” というキーワードを入力する
Then “検索” を含む2件のドキュメントが返される
And それぞれのマッチ箇所のスニペットが表示される
この2層の記法を採用しているのは、この変更の仕様が変更全体の実装・テスト設計の唯一の起点になるからです。
後続の実装タスクも、E2Eテストも、すべてここに書かれたシナリオから派生します。逆に言えば、ここで仕様が曖昧なまま進むと後からの手戻りが大きくなるということです。より網羅性の高い記法が必要だった、というわけです。
EARSとGherkinで書かせることで、その曖昧さをdelta specステップで潰しておく、というのがmspecの思想です。
インデックス構築のFRが抜けていないか、受け入れシナリオは実際に確認できる形かを引きながら確認すると良いでしょう。
設計とアーキテクチャを確かめる
次のステップは調査(research)と設計(design)です。
調査ステップでは、既存の docs/ ローダーを使い回せるか、FlexSearchとMinisearchどちらが軽量か、といった調査が行なわれます。
調査結果は、論点・採用案・代替案・根拠の4列テーブルで整理されており、なぜその案を選んだかの根拠を参照できる形で残します。
Proposalステップで決めきれていないOpen Questionsもこのタイミングで調査され、決定事項として整理されるので、後から見返したときになぜこの設計になっているのかが追いやすくなります。
ドキュメント全文検索の機能を足す 開発例だと調査結果はこんな感じで出てきます。

ただし、このMarkdownは後述するDoc TypeでRefernceなので気になるところがあれば確認する、程度で大丈夫です。
そしてこの調査結果を元にシステムの詳細設計であるdesign.mdが生成されます。
検索APIは既存の /api/docs ルートに乗せるといった技術方針やコンポーネント間の依存関係が整理されています。
アーキテクチャの大きな判断はここで確認しておくと、後半の実装ステップでの手戻りが減ります。
ちなみに、design.mdと同時に補足資料として、以下の資料も作成されます。
design-rationale.mdは、なぜその設計を選んだのかの意思決定の背景を語る文書です。全文検索の例なら、なぜsrc/search/に独立モジュールを切ったのか、なぜFlexSearchを採用したのかといった判断の経緯がresearch.mdよりわかりやすく記載されています。architecture-overview.mdは、コンポーネント間の依存関係を俯瞰した全体図のMermaidドキュメントです。図を用いて実装前に全体像はこうなるというイメージを持てます。quickstart.mdは、実装完了後にゴールデンパスを手で確認するための手順書です。「localhost:3000/searchを開いてキーワードを入れると結果が出る」という確認の流れが書かれているので、実装が終わった後に開発者が実際に動かして確認できます。
これらのドキュメントは同じ設計情報を異なる切り口で表現しています。
細部にまでフォーカスしたければ、design.mdを見て、設計の意図を理解したければdesign-rationale.mdを読むという選び方ができるのも特徴です。
実装前にチェックリストを押さえておく
次のステップでは、checklist.mdを作成し、AIエージェントによるself-reviewを実施します。
checklist.mdにはFRのカバレッジ、リグレッションリスク、動作確認項目が整理されています。
このチェックリストは、人間が確認するためだけのものではありません。
mspec内部でAIエージェントがセルフレビューを行なうとき、各アーティファクト間に矛盾がないかを確認するための起点になっています。
続く self-review ステップでサブエージェントがチェックリストを参照しながら全アーティファクトを横断するのも、この構造があるからです。
また、mspecでは実装とテストは必ずセットになっています。
チェックリストの項目のうち、自動テストで検証できるものは、テストが通ったあとに自動でチェックされます。
全文検索の例なら、FR-001 の検索機能が動くかは、自動テストが通った時点でチェック済みになります。
一方、人間でしか確認できない項目(UIの見た目、操作の自然さ、エッジケースの感覚的な妥当性など)については、<!-- verify: human --> のコメントと具体的な確認手順が併記されています。
すべてAIエージェントが品質保証するわけではなく、重要なところは人間が確認するという設計になっています。

archiveで完了
最後のarchiveステップでDelta Specが正式な仕様(SoT)にマージされて、1つの変更が完了します。
SoTは同じくMarkdownでレポジトリ内にfeatureごとに格納されるほか、Web UIでもわかりやすく可視化されます。

これがmspecの一連の体験です。
12ステップが重いとき
正直、12ステップは誤字修正やワンライナーのバグフィックスにはオーバースペックです。
そのため、他にtypo / minor / bugfixの3モードを用意しています。
typoとminorはproposalとquickstartを飛ばし、bugfixはそれに加えて根本原因分析のために research だけを残す、という具合に必要なステップだけを残します。
/mspec:new を叩いたときにAIエージェントが判断し、モードを自動設定します。
仕組みの裏側 ― 34つのM
使い方がわかったところでここからが本題です。
mspecは34つのMを軸に設計されています。その設計意図も含めてご紹介します。
Manifest ― 読み手の意図を宣言する
最初のMは、AIが書くドキュメントの読みにくさへの対策です。
ここで参考にしたのが Daniele Procida が提唱した Diátaxis というドキュメンテーションフレームワークです。
ギリシャ語の dia(across)+ taxis(arrangement) に由来する造語で、Cloudflare のドキュメントでも採用されているので、ご存じの方も多いと思います。
Diátaxisは、技術文書を読み手のニーズで4象限に分類します。
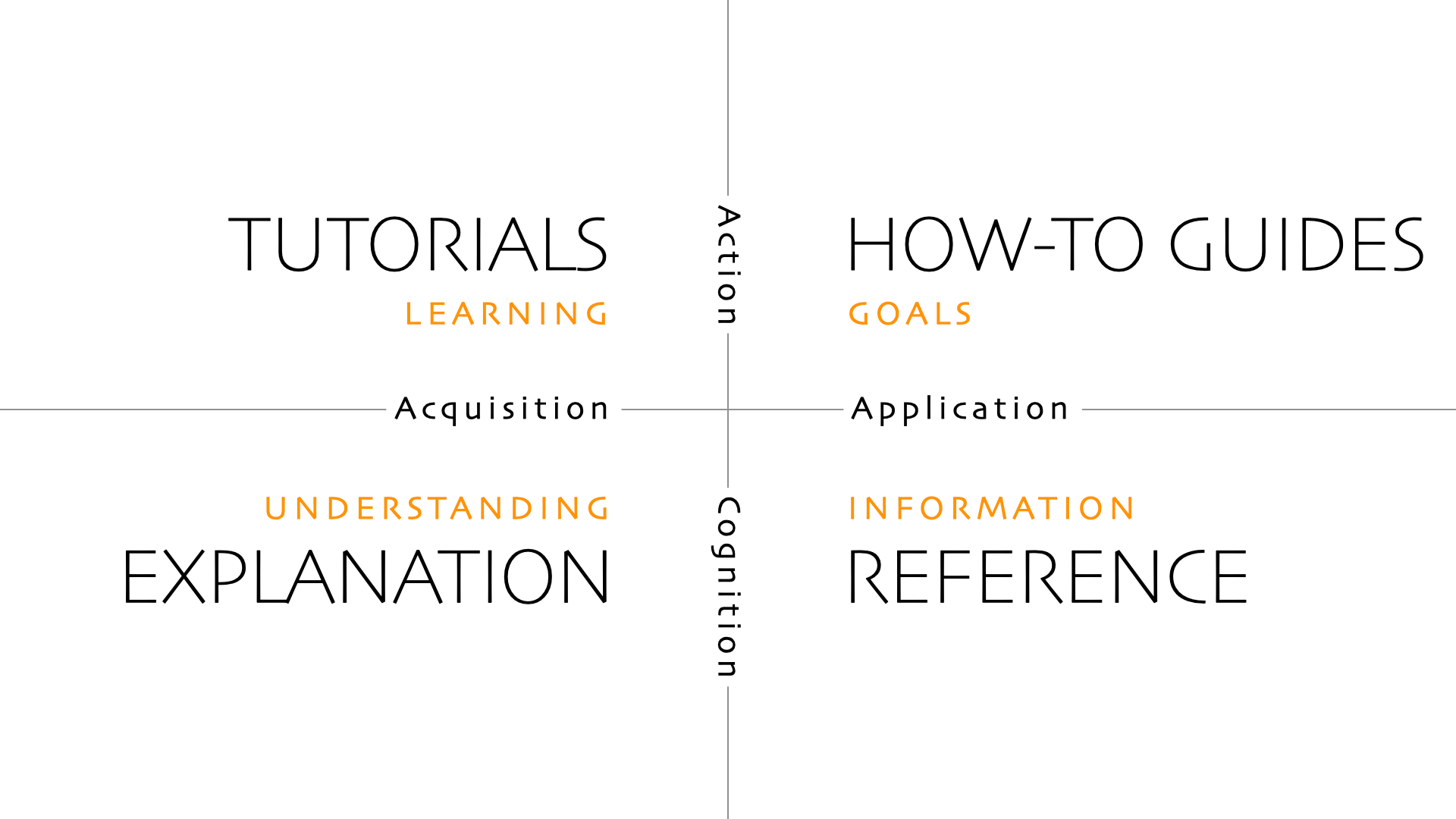
Tutorials(学習)・How-to guides(目標達成)・Reference(情報参照)・Explanation(理解) の4つに、読み手がいま行動したいのか理解したいのか、知識を習得する段階なのか応用する段階なのか、という2軸で分けるのが特徴です。
mspecでは、ワークフローが生成するすべてのMarkdownアーティファクトにYAML Front Matterで doc_type:の指定を必須にしています。
たとえば proposal.md は変更の理由を語る Explanation、 quickstart.md は手順を追う How-to、 tasks.md や glossary.md は引きやすさ優先の Reference、という割り当てです。
ちょっと感覚がずれるところとして、 tasks.mdをHow-toではなくReferenceにしている ところがあります。
これは、tasks.mdを読むのは人間ではなく実装時のAIエージェントであり、人間用の手順書ではないためです。
doc_typeを宣言することで、書き手のAIにはいまからReferenceを書くんだ、網羅と表形式を優先しようというプロンプト的な制約が入り、読み手の人間にはここは Reference だから流し読みで該当箇所だけ引けばいいという認知を与えられます。
大量のドキュメントで疲弊しない仕様駆動開発がしたい、という気持ちから生まれたアプローチです。
この読み手の理解を意識するという発想は、 Thoughtworks が公開した The Future of Software Engineering — Retreat Findings(2026年2月)で語られていた、こんな一節とも重なります。
Losing that channel without replacing it creates a comprehension gap that compounds over time.
理解のギャップが時間とともに積み重なっていく、というわけです。
AIエージェントがドキュメントを大量生成できる時代だからこそ、読み手が何を理解すべきかを見失わない仕掛けがいると思ってます。
Mapped ― 仕様とコードを物理的に紐づける
2つ目のMは、Spec Driftへの答えです。
@mspec-deltaアンカーというものを、実装コードの先頭にDocstringのような形で書き込みます。
/**
* @mspec-delta 2026-05-29-093015-add-search/specs/search-engine/spec.md
* Requirements implemented: FR-005, FR-007
* Change: add-search
*/
export function searchDocs() { /* ... */ }
配置ルールはシンプルで、ファイル先頭にコメントの形式で置きます。
1ファイルに複数アンカーを置いてもいいですし、テストファイルではファイル先頭かdescribeブロックの先頭に置きます。
(なぜこの3行コメントなのか、というのは Anchor Reference に採用しなかった案とセットで書いてあります)
3行コメントはどんな grep でも、どんなAIエージェントのコンテキストウィンドウでも扱えます。
mspec CLIは構造チェックだけ足してあげればよい、というシンプルな分担にすることで、コードと仕様のドリフトを物理的に防ぐことができます。
細かい挙動の話
(興味のある人だけ読んでください)
アンカーは3つのmspecCLIコマンドで決定論的に扱われます。
mspec anchor checkで仕様ファイルやFR-IDが存在しないアンカーを報告mspec anchor list --orphansで削除済み変更を参照している孤児アンカーを洗い出しmspec anchor extract <change-name>で どのコードが何のFRを実装したかをJSONバンドルにして書き出し
アンカーがコードや仕様に正しく対応しているかをCLIがチェックし、コードの変更に合わせてアンカーも更新されることで、コードと仕様が物理的に紐づいている状態を機械的に保ちます。
また、mspec anchor extractは少し特殊で出力したJSONをそのままClaude Code渡すことで、その変更に閉じたコード網羅レビューがLLMで回せます。
つまり、検証ゲートではLLMを使わないが、深掘り分析にはLLMをガッツリ使えるように、CLI側から決定論的に集めた素材を渡せるわけです。
そして implement ステップでは、Delta Specに書かれた FR-NNN のうち、コードアンカーが1つもないFR-IDがあれば実装ステップを完了できないという縛りがかかります。
合わせて、Delta Spec内の #### Scenario: ブロックに対応するE2Eタスクが tasks.md にあるかも見ており、シナリオとテストがズレないようになっています。
Machine-checkable ― 決定論でゲートする
3つ目のMは、LLMがLLMを採点する閉鎖ループと、形骸化するTDDへの答えです。
ワークフローの意思決定が起きる場所では、必ずCLIが パーサーまたは正規表現 で答えを出します。
FR-NNNの一意性とScenarioブロックの存在を強制したり、enforce_anchor・enforce_e2e・enforce_tddというフラグでそれぞれアンカー・E2E・テスト順序を強制します。
TDDの形骸化に対しては、 mspec test expect-red と mspec test expect-green という2つのコマンドで、テストの実行順序そのものを証跡として記録するという素朴なアプローチを取っています。
CLIが期待する終了コードに合致しないとexit 1を返すので、expect-redを踏んでいないタスクのexpect-greenを拒否できます。
test:
runners:
- name: main
# mspec test expect-red/expect-green が叩くコマンド
command: "vitest run"
# この終了コードならテスト失敗(Red)とみなす
expect_red_on_exit: [1, 2]
# この終了コードならテスト成功(Green)とみなす
expect_green_on_exit: [0]
これにより、実装に合わせてテストを後から書き換えるとか、テストを消して実装に合わせるといったAIエージェントの乱暴な動きを、CLIのゲートで弾くことができます。
ただ、正直に書くと、この仕組みはまだ完成にはほど遠いです。
Red→Greenの順序を守らせたところで、 その中身が本当に振る舞いを表したテストか までは保証できません。このあたりはドッグフーディングしながら少しずつ育てている段階です。
Middle-loop ― どうしても人間が見たほうがいい判断には人間を置く
どうしても人間が見たほうがいい判断 には、ちゃんと人間を置こうと思っています。
その代表が、 checklist と self-review がセットになった設計です。
checklist.md はAIエージェントがサブエージェントで生成する、FRカバレッジやリグレッションのリスク、動作確認項目をまとめたものです。
AIが自分でやったことを自分でチェックするための成果物ですね。
そのチェックリストのうち人間で見たほうがいいものは、AIでは完結せず人間が見て最終確認します。
AIの自己評価に依存せず、人間の目を通すわけです。
もう1つのこだわりが、さきほど少し触れた問答(ask_questions) です。
仕様駆動開発のドキュメントは、AIが書くけど人間が読む ものになります。
しかし結局のところ、一発合格とはならずAIが下書きしたMarkdownを人間が清書することが圧倒的に多くなります。
なので、mspecでは AIが人間にチャット形式で問いかけ、その回答からMarkdownの中身を補完していくという体験を優先しました。
proposal / research / design / implement にはask_questions: trueが立っており、対応するskillがClaude Codeの AskUserQuestion ツールを呼べます。
人間は 膨大なMarkdownを直接編集することなく、問答に答えるだけで仕様を肉付けできるわけです。
すべてをAIに任せきる のではなく、任せきれない判断の部分に人間を賢く使うループこそが、トータルの品質カバレッジを上げると思います。
ちなみにどこに人間を残すかという問いは、どうやら私だけの悩みではないようです。
さきほども引いたThoughtworksのレポートでは、コードを書くこと(inner loop)とCI/CD・デプロイ(outer loop)のあいだに middle loop という新しい仕事のカテゴリが生まれていると論じられています。
The retreat identified a third: a middle loop of supervisory engineering work that sits between them. This middle loop involves directing, evaluating and fixing the output of AI agents.
AIエージェントの出力を指揮・評価・修正する、監督的な仕事のことですね。 checklist と self-review、そして各ステップの人間確認ポイントは、このmiddle loopをmspecなりに形にしたもの、と言えるのかもしれません。
Thoughtworksを読んでmspecに4つ目のMを足すことを思いつきました。Middle Loopです。
Delta SpecとOpenSpecとSpec Kitと
3つのMの設計は、当然ながらゼロから降ってきたわけではなく、 既存の仕様駆動フレームワークの良いところをかなり拝借しています。
特に、 Spec Kit と OpenSpec をすごい参考にしています。
ChangesからSoTの管理方法などはOpenSpecをかなり踏襲していますし、quickstart.mdやchecklist.mdなどの品質ゲートの考え方はSpec Kitからの影響が大きいです。
オマケ機能
34つのMが骨格ですが、ドッグフーディングを続けるなかでこれも欲しいと足してきた機能がいくつかあります。
プロトタイプ(visual-mock)ステップ
UIの変更を仕様書に起こそうとして、うまく言葉にできなかったこと、ありませんか。
このボタンの色をこうしたい、画面全体の背景はこの色でみたいな話は、振る舞いベースの仕様の書き方ではどうにも表現しにくいんですよね。
そうして曖昧なまま作られたUIは、最後の実装ステップで実物を触ってはじめて思ってたのと違うとなりがちです。
それならバイブコーディングで実装と確認のループをたくさん回したほうが圧倒的に早いし楽です。
仕様駆動とUIのスタイル、特に見た目まわりの相性の悪さは、私のなかでずっと課題でした。
mspecではUIやスタイルに影響する変更と判断した際、仕様を固める前に、まず簡単なプロトタイプを作って認識を合わせることをします。
それがワークフローの /mspec:prototype ステップ(ステップidは visual-mock)です。
AIエージェントがHTMLのモックアップを生成してWeb UI経由で表示し、ユーザーからのフィードバックをprototype-feedback.mdに収集します。
仕様策定のいちばん初期に、見た目の認識だけ先に合わせてしまうわけです。
Web UI
仕様駆動開発を回すと、生成された大量のMarkdownを、ひたすらエディタで開いて確認することになります。疲れますよね。
私はコードを書くときはIDEの設定をダークモードにしているのですが、どうにもMarkdownを読み切れていない気がしていました。
そんな悩みを持っているときに、ダークモードは本当に読みやすいのか?コントラスト極性の研究から考える表示モードの設計の記事を読んで、思い切ってライトモードにIDEの設定を切り替えてみました。
文字を正確に認識する・校正するようなタスクでは、正のコントラスト極性(ライトモード)が有利な傾向があるとのことで…。
なるほどと思って、仕様書を読むときだけライトモードに切り替えてみたのですが、今度は コードを読むときに目が痛くなりました。困りましたね…。
そこで気づいたのが、そもそも仕様駆動開発のアーティファクトとコードは、別のUIで見たほうがいいんじゃないか、ということでした。 ならフレームワークのなかで完結させよう、と作ったのがこのWeb UIです。
実際にMarkdownを可視化するものを作ってみると、 Kindle のセピアやグリーンのような色合いがとても読みやすくて、私はmspecを使うときは基本グリーンの背景にしています。

目に優しいし、視認性も高いんですよね(気のせいかも)。
(実験的な機能)FR単位のリスク分類
AIにレビューや実装をやらせていると、どんな変更も同じ頑張りで、律儀に厳密に扱おうとするのが気になりませんか。
Typo修正も、決済まわりの根幹も、同じ厳密さで進めてしまいます。
人間のレビュアーなら、ここは軽く流す・ここは全力で見る、という強弱を自然につけるところです。
この感覚もまた、さきほど引いたThoughtworksのレポートのなかで、はっきり言語化されていました。
Not all code carries the same risk. […] instead of asking “did someone review this code?” organizations need to ask “what is the blast radius if this code is wrong, and is our verification proportional to that risk?”
コードの blast radius(影響範囲)でリスクを評価し、検証コストをリスクに比例させようという考え方です。
mspecではこの考え方を、Delta SpecのFR単位で risk_tier(critical / standard / trivial)と blast_radius(local / module / system / external)を宣言する形に落とし込みました。
どの要件がどれだけ危ないか、影響がどこまで及ぶかに色をつけておくわけです。TierごとにProposalステップで質問される内容、特にセキュリティ周りの質問の数や質が変わってきます。
ですが、mspecを使ってもセキュリティ的な観点の洗い出しはまだ甘いです。なので実験的機能にとどめておきます。
リスクの線引きを固定ルールで縛るべきか、AIに柔軟に判断させるべきかは、自分のなかでもまだ答えが出ていません。
アーカイブから学ぶ
仕様駆動で進めていて、実装ステップあたりで違ったと気づくことってありませんか。
要件定義から着々と下ってきて、いちばん最後の後戻りしにくいところで、お客さんとの認識がズレていたと気づく感覚に似ています。
要因はいくつもあると思っています。
Proposalの段階で自分の要求やコンテキストをAIエージェントに伝えきれていなかったのかもしれないし、出来上がったアーティファクトを人間が読みきれず、潰すべき点を見逃したのかもしれないし、単純にAIの生成のブレもあるでしょう。
だからこそ、その失敗をちゃんと振り返って次に活かしたい。人間が振り返るのはもちろん、AIにも振り返りのきっかけを渡したいと思ったのが、この機能の出発点です。
着想の1つになったのが、AWSが提唱する AI-DLC(AI-Driven Development Life Cycle)Workflows 2.0 の仕様書です。
2.0では、ワークフローを構成する各 Skill が「生成仕様・自己検証仕様・学習仕様」という3コンパートメントモデルを持つことが定義されています。特に Principle 9 — Learning from Practice では、こう述べられています。
Today, when a human corrects an AI output, that correction is typically applied once and forgotten. Under Principle 9, every correction is a candidate learning.
人間がAIの出力を修正しても、今まではその修正は一度きりで忘れ去られていた。すべての修正が次の学習の候補になる、という考え方です。この実践から学ぶという発想に触れて、変更が閉じたあとにフィードバックを回収するループもフレームワークに組み込めないか、と考えました。
それが mspec learn です。アーカイブ済みの変更から、次に活かせるレッスンと、今回はやりきれなかったけれど重要なネクストアクションを拾い上げます。
学びとして有用と人間に選択されたレッスンはmemoryとして、次回変更時の憲法ファイルに追記されます。
ネクストアクションは、そのまま /mspec:new のプロンプトに渡され、次の変更の起点(changesディレクトリの作成)になります。
ただ、まだ完成形にはほど遠くて、拾ってくるレッスンが そのセッションでしか起きないような具体的すぎる内容 に寄りがちです。
このあたりのチューニングは、これからの課題ですね。
最後に
長々と書きましたが、mspecは既存の仕様駆動開発に対する、私個人の違和感を埋めるためのフレームワークです。
仕様駆動開発フレームワークを自作する意味は、正直あまりないかもしれません。
既存のフレームワークも十分にカスタマイズできますので。
ただ、自分で作ってみると、自分自身が開発という文脈においてAIに何を求めているのか、何が課題なのかを可視化する良い機会になります。
mspecのM は、最初は私の飼い犬であるむぎのむから取ったむぎぼーspecという意味でした。それくらい何の考えもなしにとりあえず作ろうかなと思った感じです。
開発を進めていくうちに アンカーで仕様とコードを紐づけるMapped という考え方から、 読み手の意図を明示するManifest、 CLIで決定論を保つMachine-checkable が見えてきて、 さらには、人間を監督者として置くMiddle-loopの4つのM に育ってくれました。
![]()
むぎぼーのおかげですね。むぎぼーすごい。
むぎぼーは2歳になりました。これからも元気に長生きしてほしいですわん。
tubone24にラーメンを食べさせよう!
ぽちっとな↓
